1. Introduction
The overgrowth of algae, known as algal blooms, has been a continuous global issue in the management of freshwater systems for several decades. It is affected by various physical factors (e.g., temperature and sunlight) [
1,
2,
3,
4] and other natural or anthropogenic factors (e.g., nutrient input, seasonal changes in water flow, and climate change) [
5,
6,
7]. Particularly, the excessive growth of harmful algal species, such as cyanobacteria (e.g.,
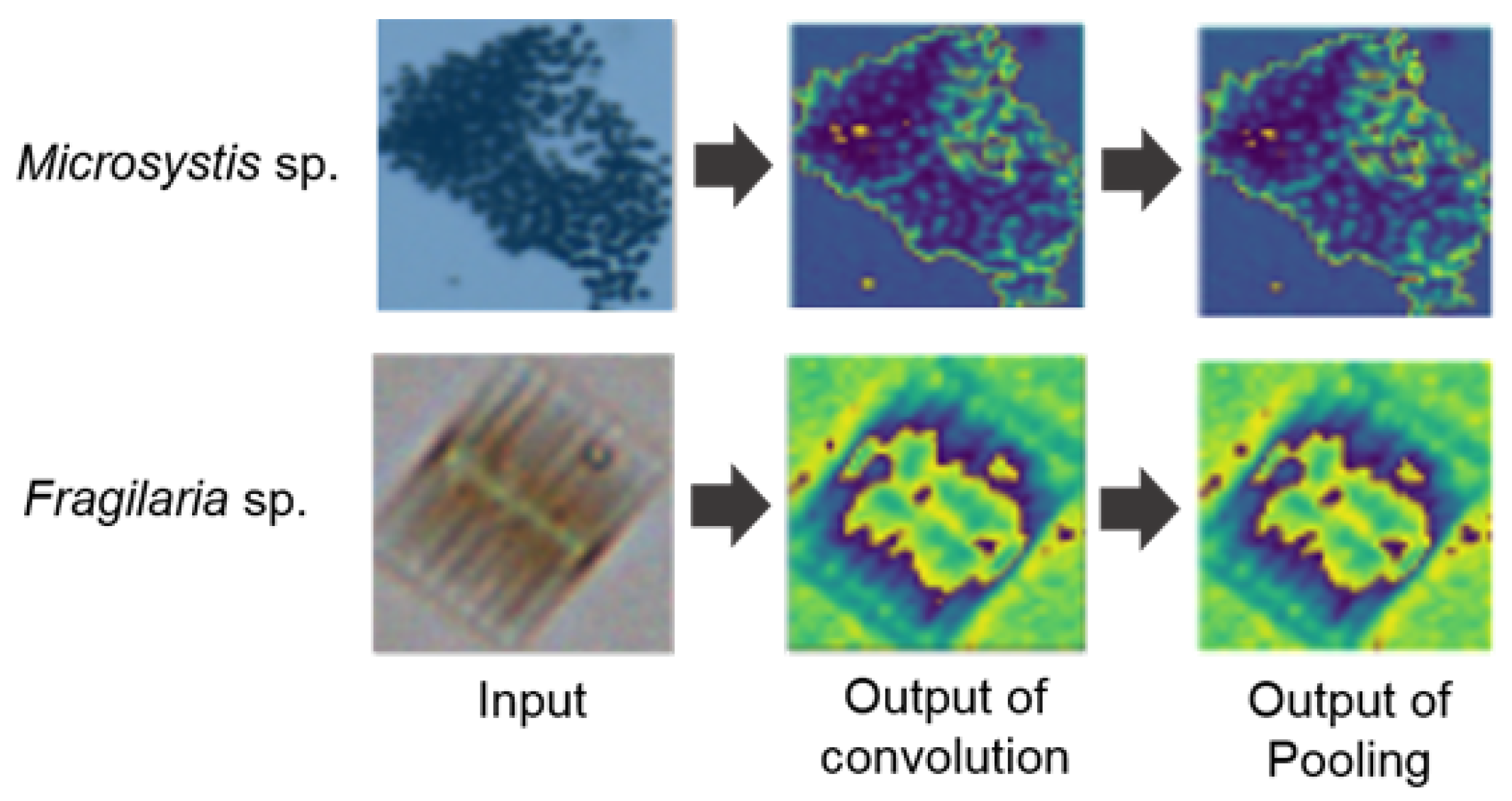
Microcystis sp. and
Oscillatoria sp.), often causes undesirable effects on drinking water quality due to algal toxins and an unfavorable odor or taste, while overgrowth of diatoms such as
Synedra sp. causes clogging of filtration systems in drinking water utilities [
3,
8,
9,
10]. Various physical, chemical, and biological methods (e.g., algaecides, nano-materials such as TiO
2, barley straw, and ultrasonication) [
11,
12,
13,
14] and the reduction of nutrients in water bodies by utilizing a wetland or a natural predator of algae, such as Daphnia, [
15] have proven effective for the control of algal blooms. While the control and mitigation of algal blooms in freshwater systems is important for safe drinking water supply, proper monitoring of the occurrence and physiological status of the algal bloom is imperative for developing effective water resource management strategies [
16]. Aerial monitoring from multi-spectral or hyper-spectral images obtained from aircrafts, drones or satellites is known to provide an effective approach for identifying algal bloom events over a wide area [
17,
18,
19]. However, direct and continuous monitoring is essential for rapid and effective operational responses in water management districts and utilities for processing drinking water against undesired algal bloom events. Although visual investigation using a microscope is one of the most conventional and widely accepted methods for algal species identification, this method is time-consuming and requires considerable labor. Furthermore, the results may be subjective and can be affected by an experimenter’s proficiency. Thus, the development of a novel technique is urgent for a rapid and un-biased identification of algal status in bloom events.
A digital imaging flow cytometer and microscope (FlowCAM) is a representative technique that has previously been widely used for the identification and classification of zooplankton [
20], and its use has been extended to other microbiological classification, including phytoplankton [
21,
22,
23]. Generally, FlowCAM identifies the morphological characteristics of algal cells and classifies algae based on measured morphological parameters, such as the shape, length, width, and area [
22,
24]. However, there exist many poorly characterized algal species that remain taxonomically ill-defined or conceptually debated [
25] and more efficient observation techniques using relatively bigger data are required for effective monitoring of algal blooms in natural systems. Recently, various machine learning techniques (e.g., artificial neural networks, support vector machine, and random forest) have been applied extensively in data management of water resources for the analysis and prediction of water quality or water flow in freshwater systems [
26,
27,
28,
29,
30,
31]. More recently, deep learning has been considered as one of the most promising machine learning techniques for image identification and analysis [
32,
33,
34]. Particularly, the convolutional neural network (CNN) is one of the deep neural networks that has been widely applied in image identification and analysis due to its ability to extract and represent high-level abstractions in data sets [
33,
35,
36,
37].
For algae image classification, only a few studies were reported in monitoring of algal blooms using CNNs [
25,
33,
38]. For example, Medina et al. [
33] applied CNN for algal detection in underwater pipelines which accumulate sand and algae on their surface, hiding damages. They used two classes of algae and non-algae (e.g., sand) and classified the non-algae group with more than 99% accuracy. More recently, Lakshmi and Sivakumar [
38] used a CNN model for the classification of Chlorella with 91.82% accuracy. However, the study used CNN architectures that were arbitrarily chosen by researcher’s experience, and did not explore possible CNN architectures which may better fit algal image data.
In this paper, a neural architecture search (NAS), an automatic approach for the design of artificial neural networks (ANN), is used to automatically examine possible CNN architectures and yield a more accurate CNN architecture for algal classification. Ordinary machine learning of ANN is a technique to find weight parameters that fit data, whereas NAS is a technique to find best structural elements (e.g., convolution layer and pooling layer) of ANN. A diverse set of solutions have been developed for NAS [
39,
40,
41]. A recent review paper introduces various techniques for NAS [
42]. Such techniques include grid search, random search, evolutionary algorithms, reinforcement learning, and Bayesian optimization. Grid search explores the best parameters among parameter spaces that were manually selected at regular intervals or grids, whereas random search uses random selection for the parameter spaces. Evolutionary algorithms [
43] are widely used for any optimization problems to find a best solution. For ANN, comprehensive research [
44,
45,
46,
47] of NAS using the evolutionary algorithms have been conducted. Another adaptable method, reinforcement learning [
48], has recently taken over from the evolutionary algorithms. Zoph and Le [
39] used a controller that constructs candidate architectures of ANN and is updated according to the performance score (e.g., accuracy (see Equation (
3) in
Section 3.3)) of the previously selected candidate architectures. The controller is another machine learning model in the framework of the reinforcement learning approaches. Zoph and Le [
39] used recurrent neural networks [
49] as the controller model to estimate the candidate architectures. Baker et al. [
50] applied reinforcement learning to CNN models for image classification. One of the most popular approaches for parameter optimization under unknown functions is Bayesian optimization. Recently, Jin et al. [
41] introduced NAS for CNN models using Bayesian optimization. In this paper, we use the Bayesian optimization based NAS from Jin et al. [
41] and introduce it in
Section 2.3.
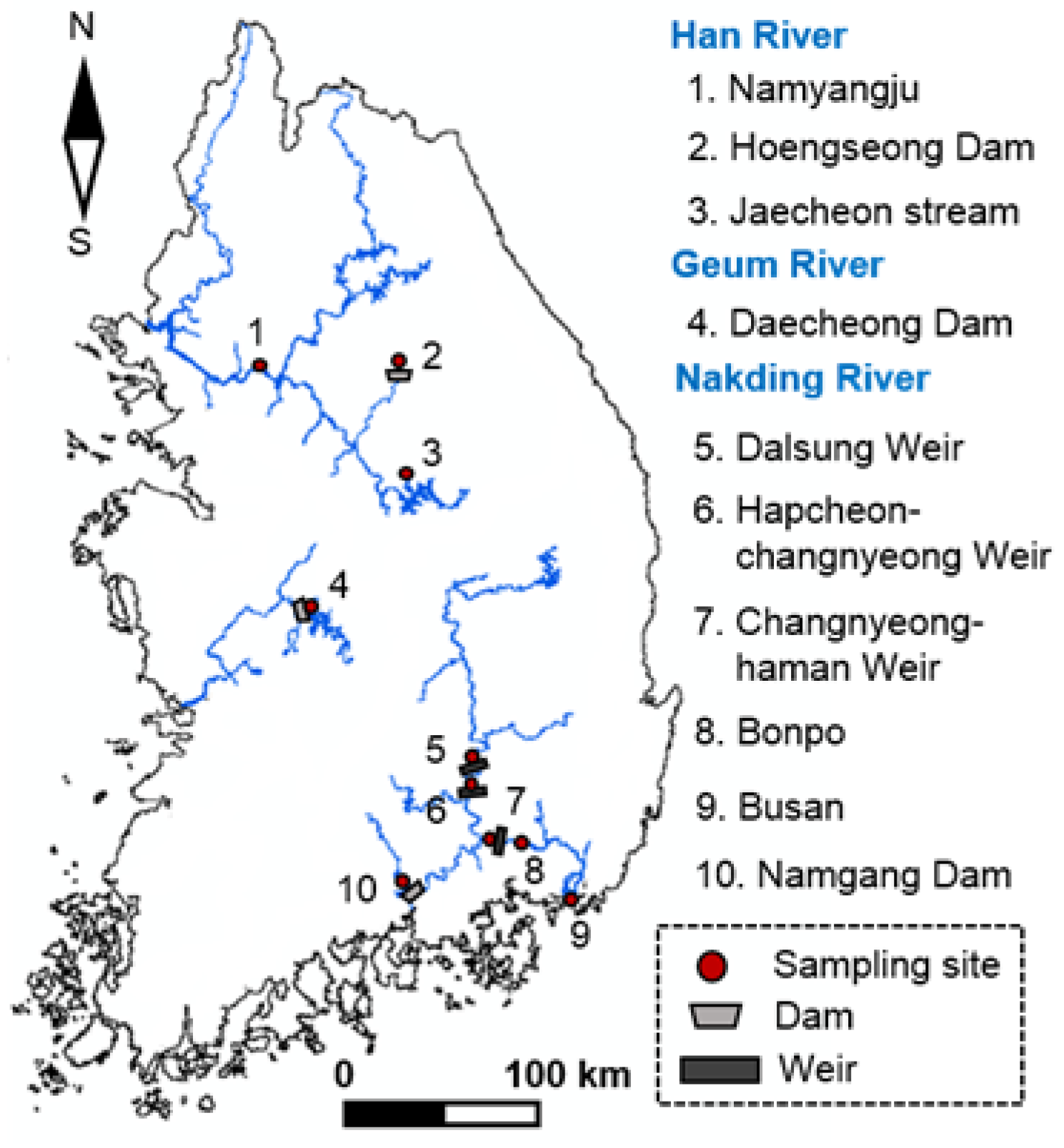
Along with this NAS approach, we introduce a framework which contains three steps (acquisition, preprocessing, and analysis) in order to support the algae image classification based on NAS. In addition, we conduct an experiment in the real-world environment to evaluate the proposed method in this paper. First, several tens of thousands of algal images are collected using FlowCAM from various natural water bodies that store run-off during the summer flooding season and provide water supply for domestic, agricultural, and industrial purposes [
51]. Then, a CNN model is constructed by NAS and is used to identify eight major algal genera including
Microcystis sp., and
Oscillatoria sp. found in harmful algal blooms (HABs) events in the major rivers in South Korea. The applicability of the model is verified from two model simulation (experiment) scenarios; (1) using original images only, (2) using augmented images by rotation or mirroring for training and validation. For testing the developed model, original images are used.
In this paper, our contributions are threefold: (i) introducing the neural architecture search approach for algal classification, (ii) suggesting the algal image analysis framework using of machine learning, and (iii) presenting the experimental results from the real-world environments.
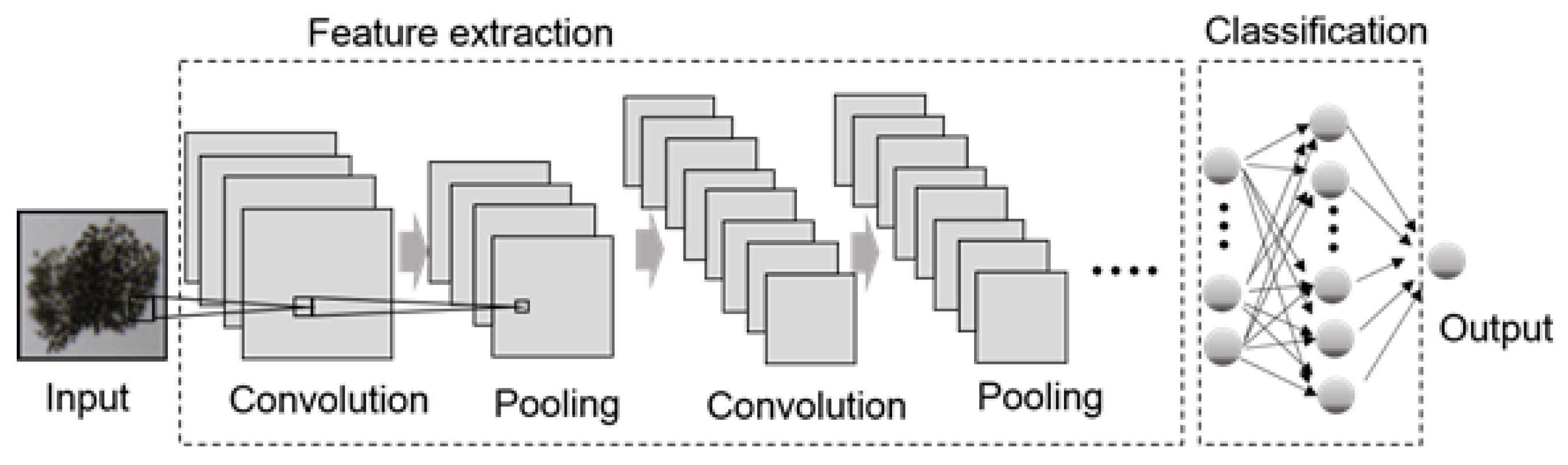
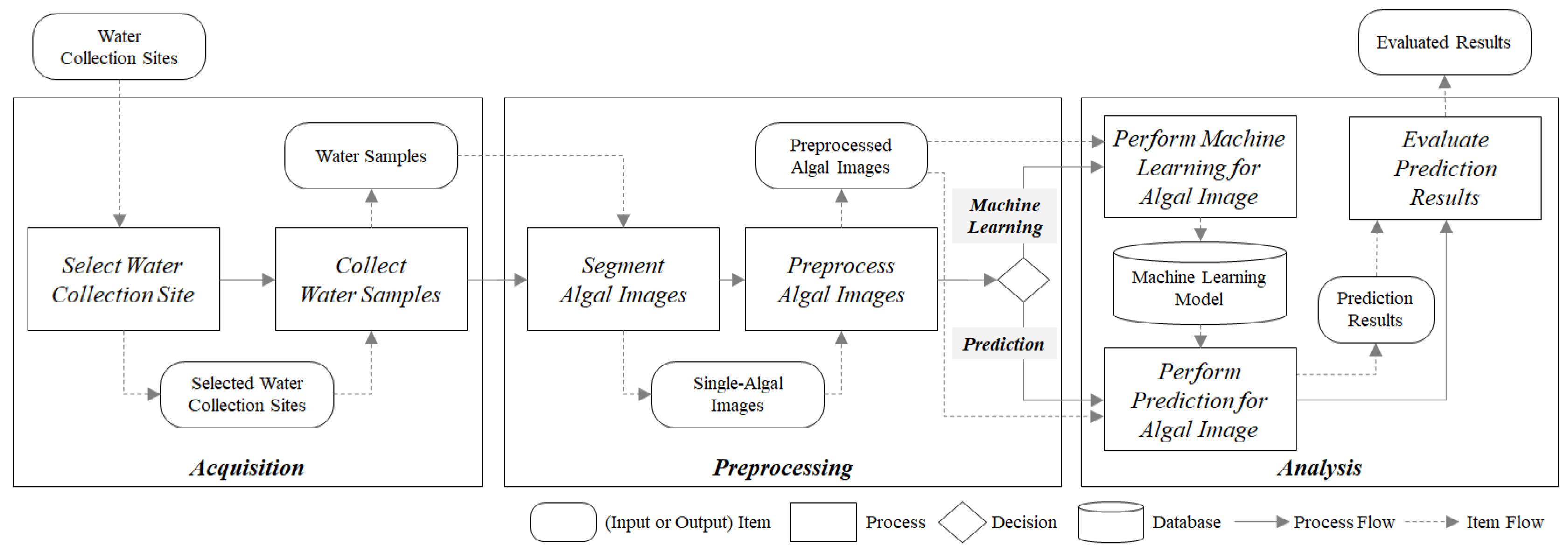
3. Framework of Machine Learning Analysis for Algae Images
Developing classification models (e.g., CNN models) can be greatly facilitated by the use of a generic framework, which provides a guideline for the development of the classification models and especially focuses on analysis of algal images. In this section, we introduce a framework of machine learning analysis for algal images (
Figure 6). The framework consists of three main processes: (1) acquisition, (2) preprocessing, and (3) analysis. The inputs of the framework are the water collecting sites (e.g., the stream or reservoir), and the outputs of the framework are the evaluated results from the algal image analysis.
3.1. Acquisition
The acquisition step defines water collection sites and performs the collection of water samples. In this step, one should define purposes of the algal image analysis (e.g., algal image classification, harmful algae detection, and algal quantity analysis). Then, one should select major places where the target algae inhabit. This step outputs water samples by means of water collection techniques (e.g., [
60,
61]).
3.2. Preprocessing
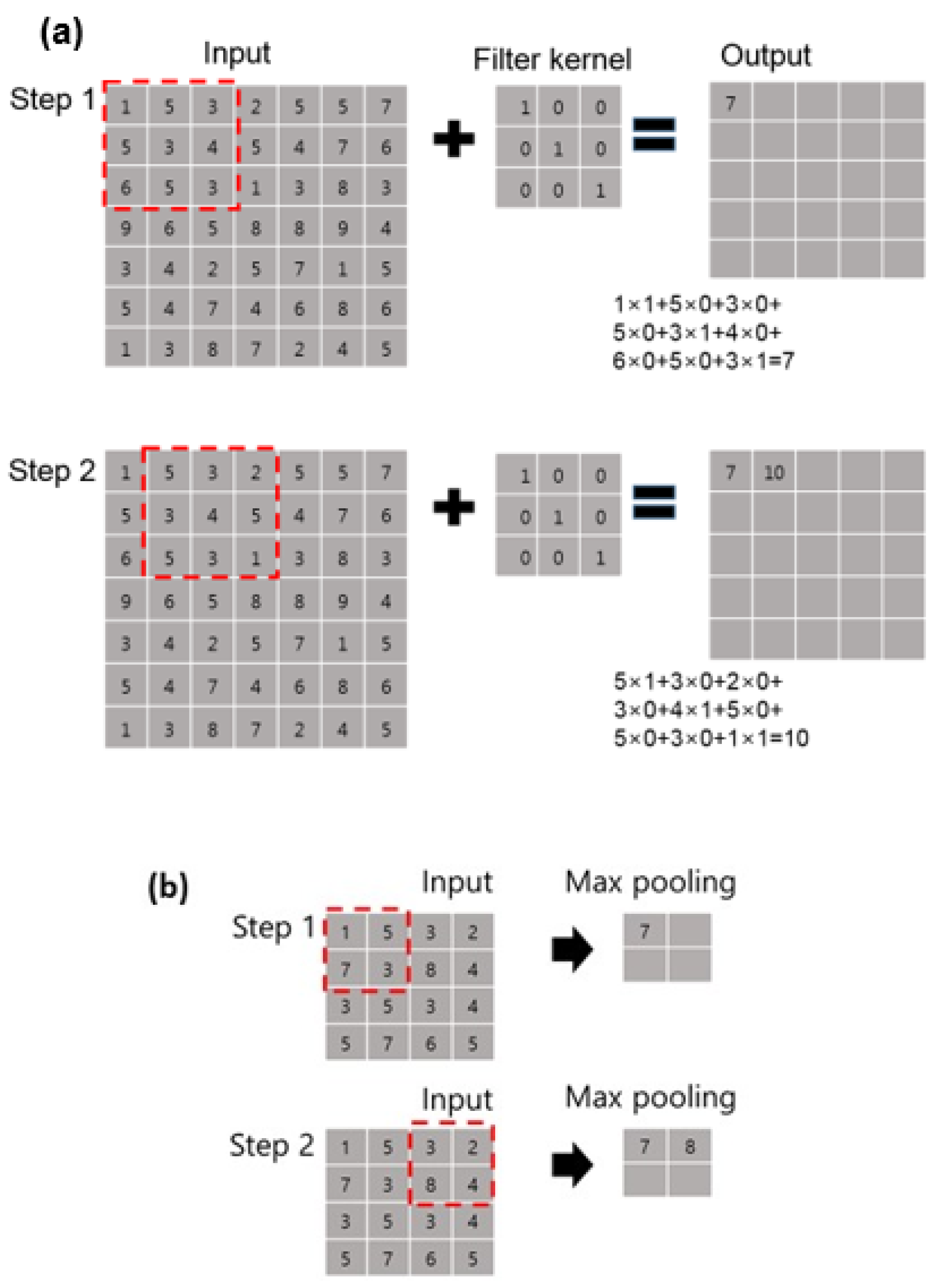
The preprocessing step aims at generating proper image data for analysis (i.e., machine learning and prediction) in the next step. The water samples from the acquisition step are captured as image data. Then, the image data are segmented according to the purpose of analysis. These sub-steps can be automated by using FlowCAM, which includes image capturing and segmentation capability. The preprocessing step contains image transformation (e.g., augmentation). Image data augmentation is the process of generating more data from the original data. In deep learning, a large dataset is crucial for model generalization, fitting well on unseen data. For image data augmentation, it is possible to apply several data transformation techniques (e.g., mirroring, rotating, scaling, and adding noise) to the original data.
3.3. Analysis
The analysis step consists of three sub-steps: (1) perform machine learning, (2) perform prediction, and (3) evaluate prediction results. In the sub-step “perform machine learning”, machine learning models (e.g., random forests [
62], Gaussian naive Bayes [
63], and support vector machine [
64]) are developed. Note that in this paper, we focus on the CNN model, a state-of-the-art deep learning model for image classification. To measure the performance of such analysis models, performance metrics are required. We introduce some performance metrics for classification.
As a classification performance metrics, the accuracy
Acc of Equation (
3), the sum of correct classification divided by the total number of classifications, can be used.
where
N denotes the number of class and
denotes the total number of the case in which values of
i-th prediction and
j-th observation are identical. Except the accuracy score
Acc, we can use precision (Equation (
4)), recall (Equation (
5)), and F1-score (Equation (
6)). These metrics can be easily calculated by using the following four indicators (TP, FP, FN and TN).
True positive (TP): the amount of the observed positive values which were correctly predicted,
False positive (FP): the amount of the observed positive values which were wrongly predicted,
False negative (FN): the amount of the observed negative values which were wrongly predicted,
True negative (TN): the amount of the observed negative values which were correctly predicted.
These four indicators can be used to define the equations of Precision and Recall as shown.
Precision is commonly used to measure the influence of false positives, while Recall is used to measure the influence of false negatives. F1-score is defined as the weighted average of Precision and Recall.
Precision, Recall, and F1-score have a score of one when the prediction is perfect. For the total prediction failure, they yield a score of zero.
After the sub-step Perform Machine Learning, the learned machine learning models are stored in a database. The database is activated to output the learned machine learning models, when inputting the request of prediction and input data in the sub-step Perform Prediction. Then, prediction results (e.g., classification results) are output from the sub-step Perform Prediction and evaluated using the purposes of the algal image analysis defined in the step Acquisition.
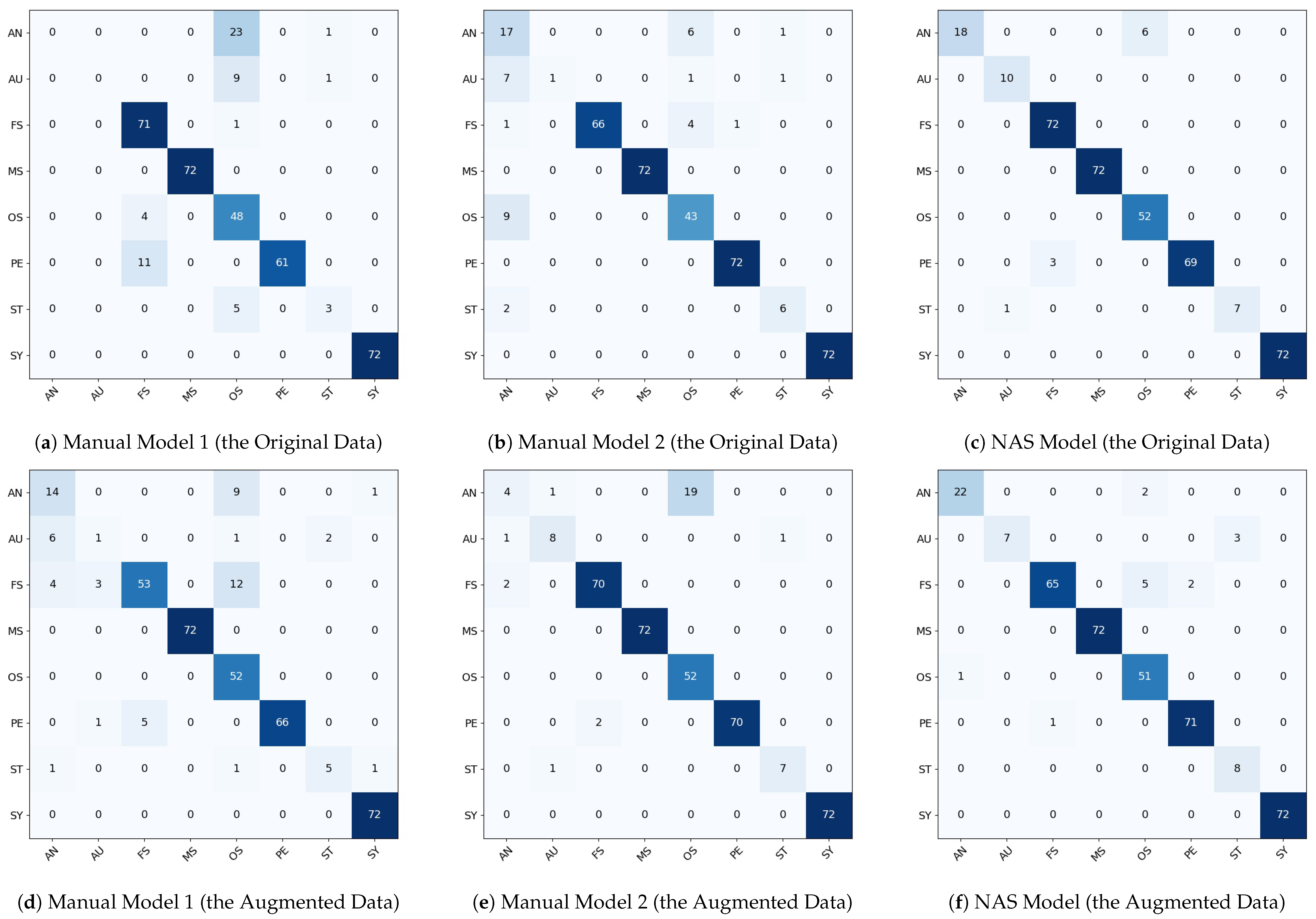
5. Discussion for the Algal Image Classification
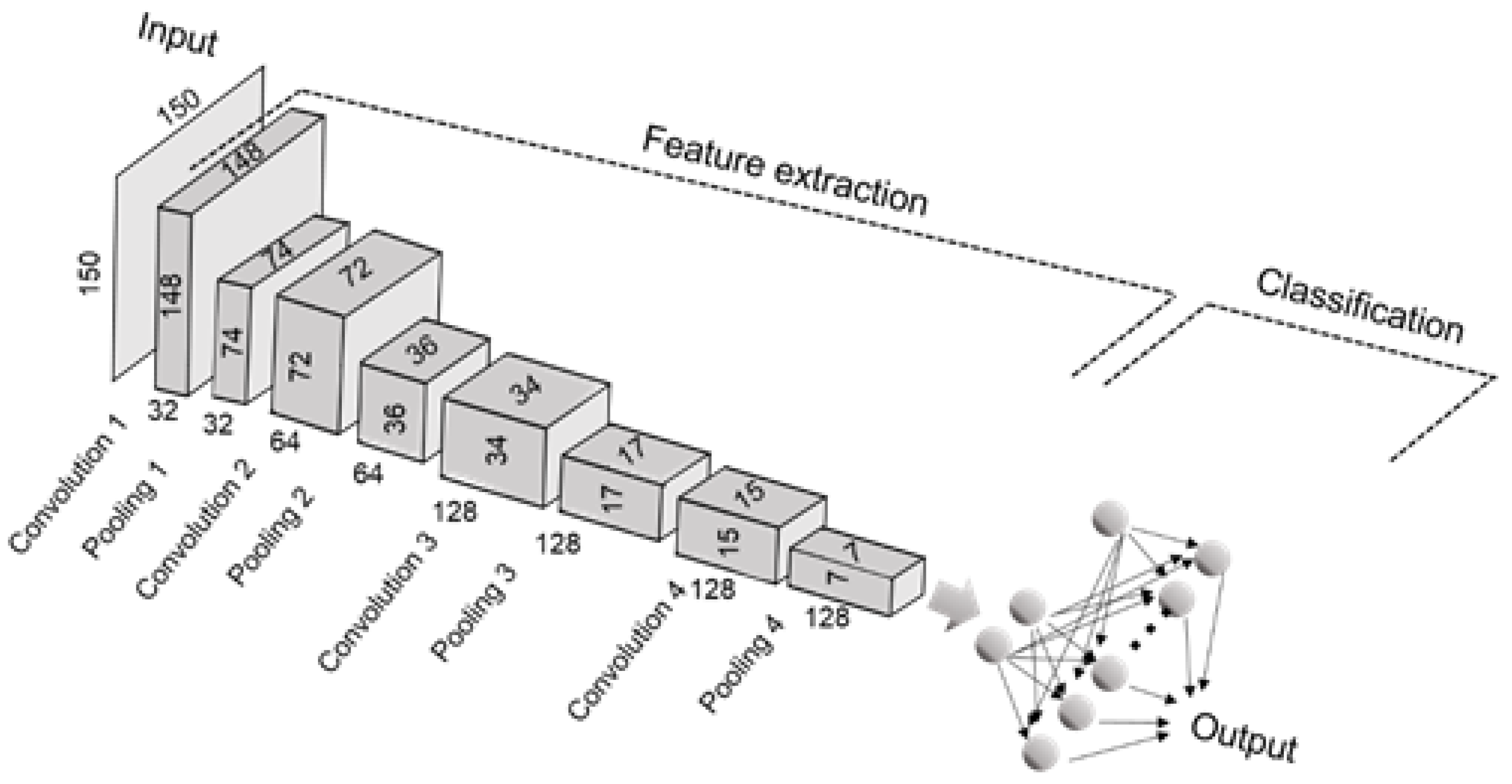
In this study, four CNN models were developed for the classification of representative algal genera of HABs from algal images obtained using FlowCAM. The NAS models developed in this paper classified the eight algal genera effectively in comparison to the manually developed models.
The results verified the applicability of the NAS technology for the analysis of algal cells at the genus level. The average F1-Score for the NAS model 1 was 0.9563 to classify the eight algal classes. This result indicated that the NAS technology can outperform the conventional CNN modeling approach. Also, the developed CNN model may be further optimized depending on the algal image library, which is used for the classification, as we can see the performance improvement of using the augmented data.
In this paper, we focused on algal image classification based on the NAS technology and its framework to lead and guide one to efficient research and applications. However, there are several future research topics. First, the CNN model developed in this study classified eight algal genera commonly found in HABs events, with no interference effect from the additional images which were not included in our model library. CNN models can misclassify images which are not included in the model library, thus reducing the reliability of the CNN model. For this, we can consider an image library platform for algal species. Obviously, the CNN model applicability can be improved by increasing the number of microscopic algal images with different algal species. Secondly, in the current development of the CNN model, there was no consideration of microalgal colonies. However, for example, a
Microcystis sp. colony typically consists of hundreds to thousands of individual algal cells. Counting individual algal cells in a colony is important to determine the physiological status of the algal bloom in freshwater systems, and is included in guidelines for general algal management [
66,
67]. To the best of our knowledge, no studies have been reported for developing automated algal cell counts. It seems that recent deep learning techniques may provide a possible approach. For example, one of the recent deep-learning techniques, U-net, is used for the segmentation of images and has been applied in the medical field [
68,
69,
70]. This may provide a possible solution for individual cell counting in the
Microcystis sp. colonies. As this method is still in the early stages of research, further studies are suggested to extend the possible application of deep learning techniques as a novel method for algal bloom monitoring.

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}