Data-Driven Approach for Leak Localization in Water Distribution Networks Using Pressure Sensors and Spatial Interpolation

 ,
,
Abstract
:1. Introduction
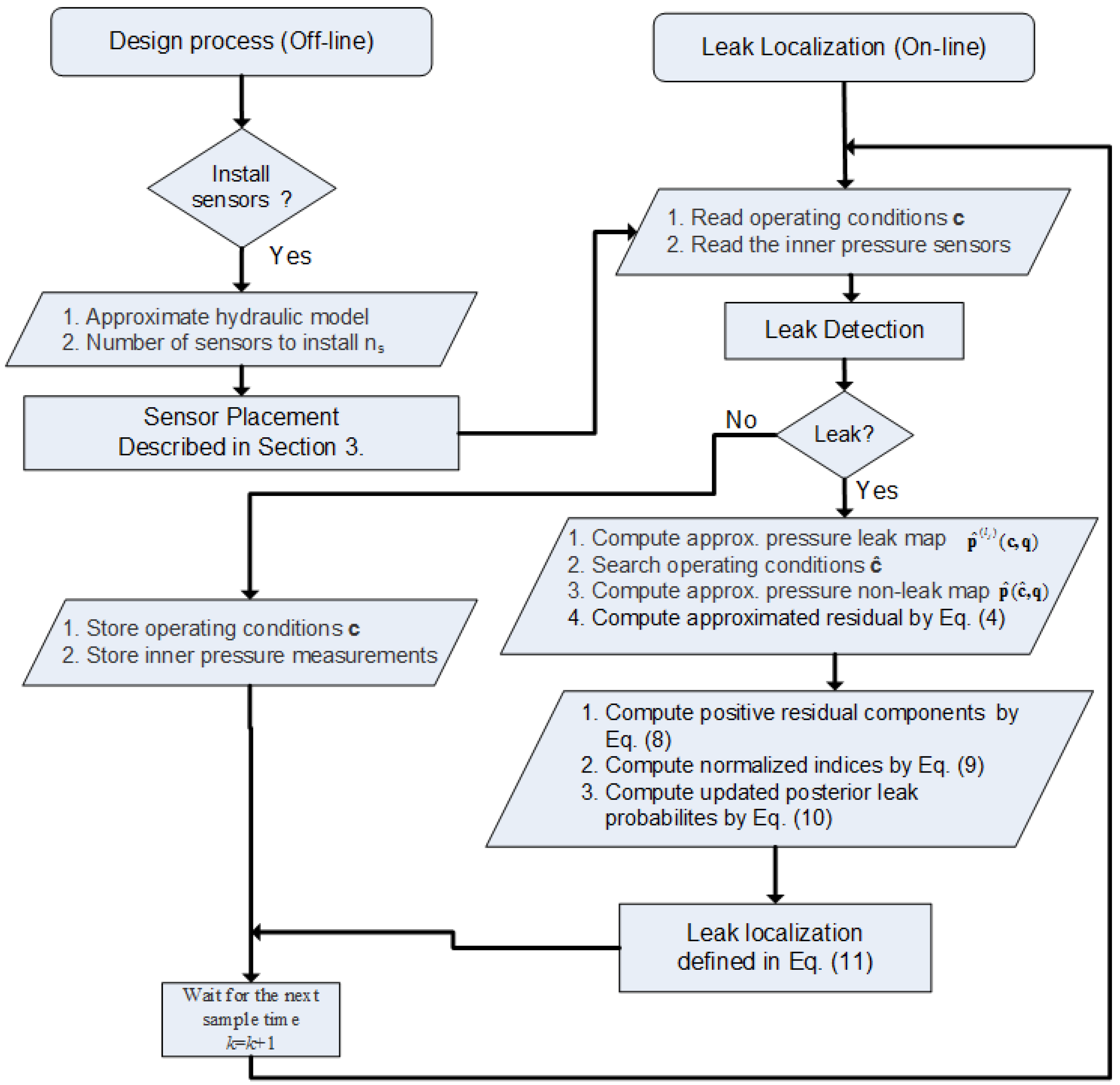
2. Leak Localization
2.1. Assumptions and Basic Operation
- is the pressure map with the WDN with boundary conditions c and leak-free case.
- is the pressure map with the WDN boundary conditions c and a leak scenario in node j with a leak of magnitude l.
- is the pressure map in the WDN with boundary conditions c in a non leak scenario estimated using q sensors. If , it is computed by using pressure recorded values ; otherwise it is computed by interpolation techniques for estimating the pressure in nodes without sensor.
- is the pressure map in the WDN with boundary conditions c and leak scenario in node j with magnitude l using q sensors. If , it is computed using the measurement values ; otherwise the pressure values are estimated by means of interpolation techniques.
2.2. Pressure Estimation by Means of Interpolation
2.3. Bayesian Time Reasoning
2.4. Performance Indicators
2.5. Summary
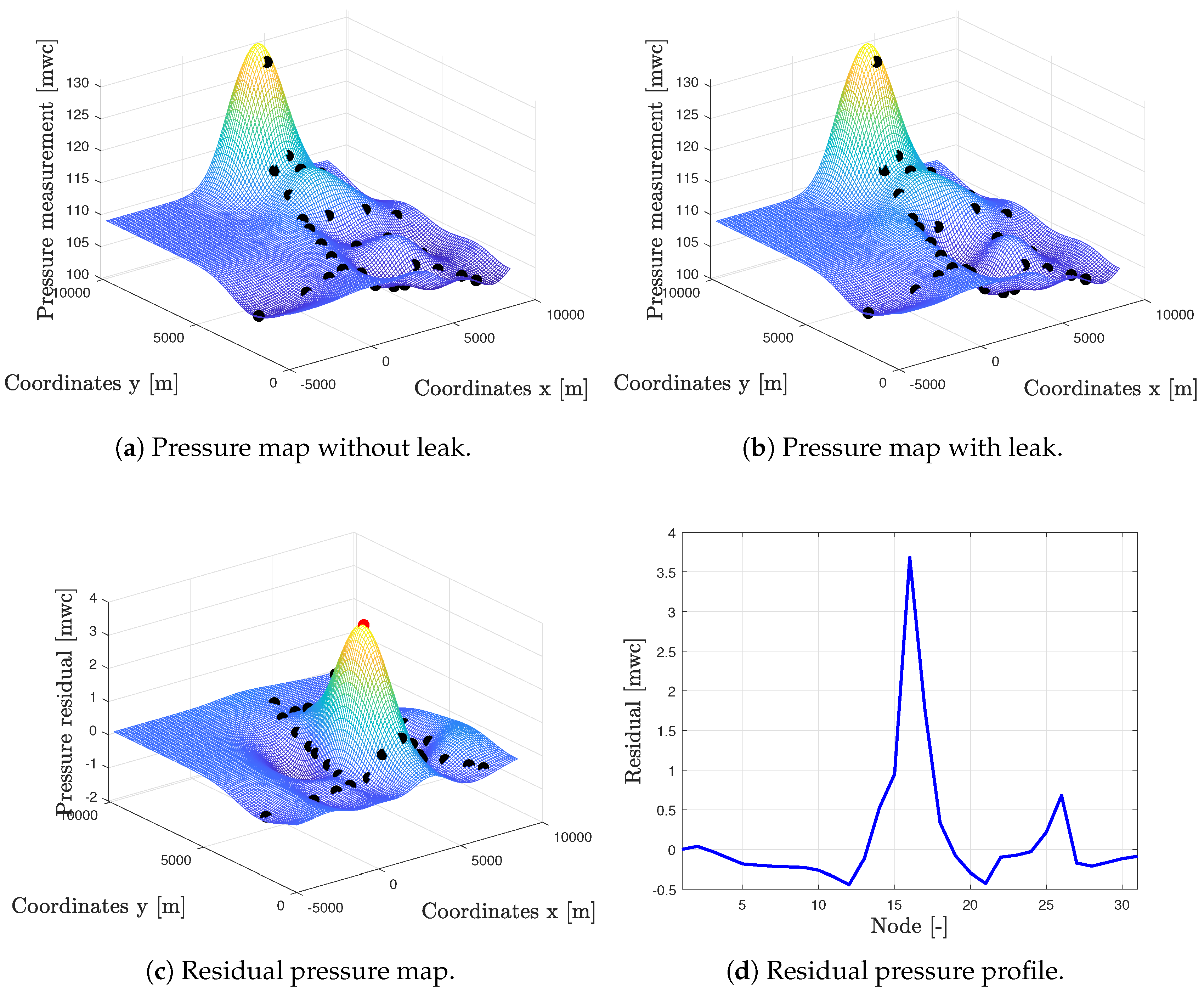
- Look for the most recent available leak-free historical data captured under similar operating conditions, i.e., at the same hour of the day and with similar input pressure and flow conditions.
- Apply Kriging spatial interpolation (6) to the selected historical values to obtain the reference pressure map, i.e., a map containing the reference pressure values for all the network nodes.
- Apply Kriging (6) to the measured values to obtain the current pressure map.
- Compare the current and the reference pressure maps by computing the residual (4).
- Identify the leaky node as the one with greatest difference between pressure maps by using (5).
- Integrate the individual diagnosis in a time horizon scheme to improve the performance by means of the Bayes rule (10).
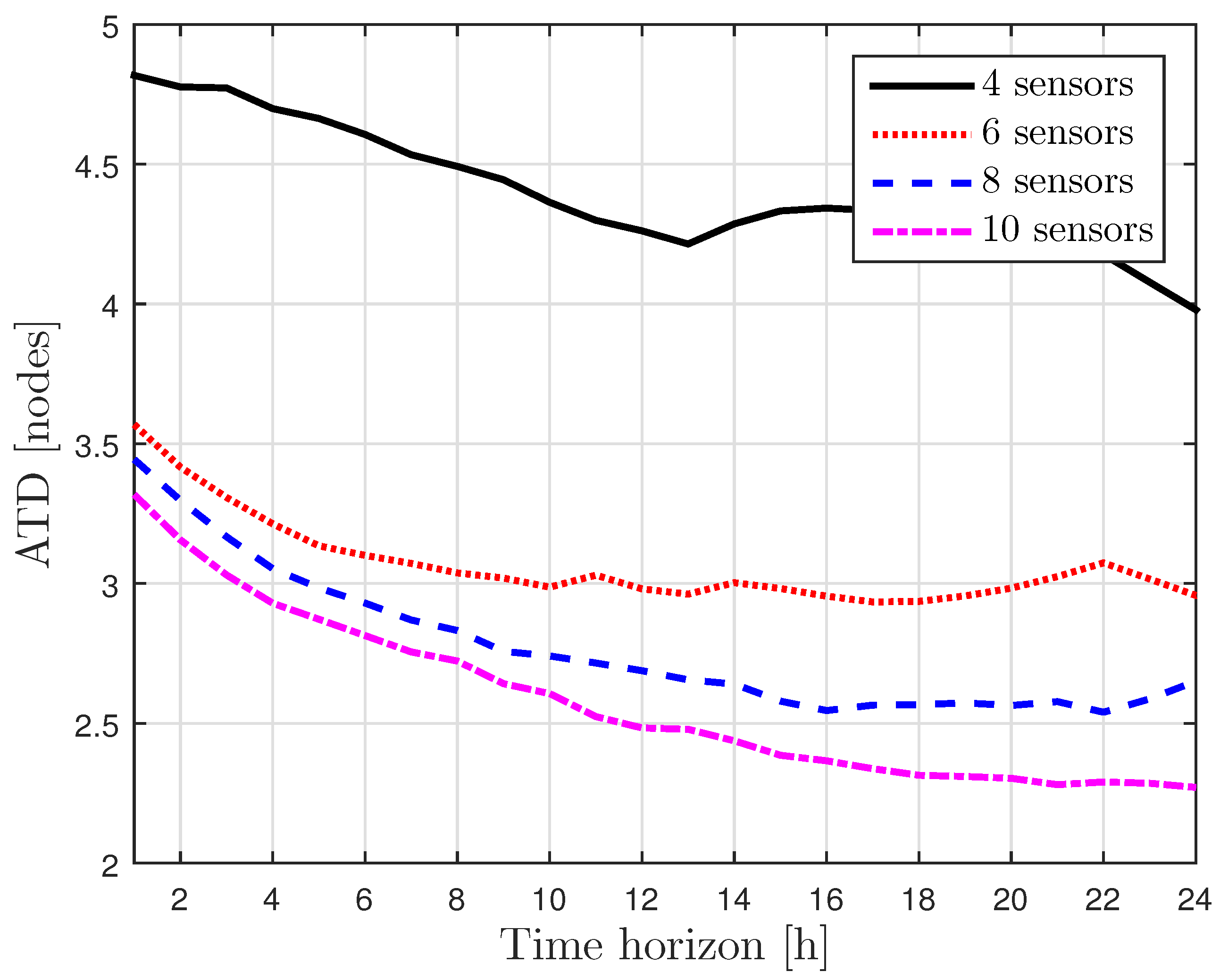
3. Sensor Placement
| Algorithm 1 Sequential forward floating search for sensor placement. |
|
4. Case Studies
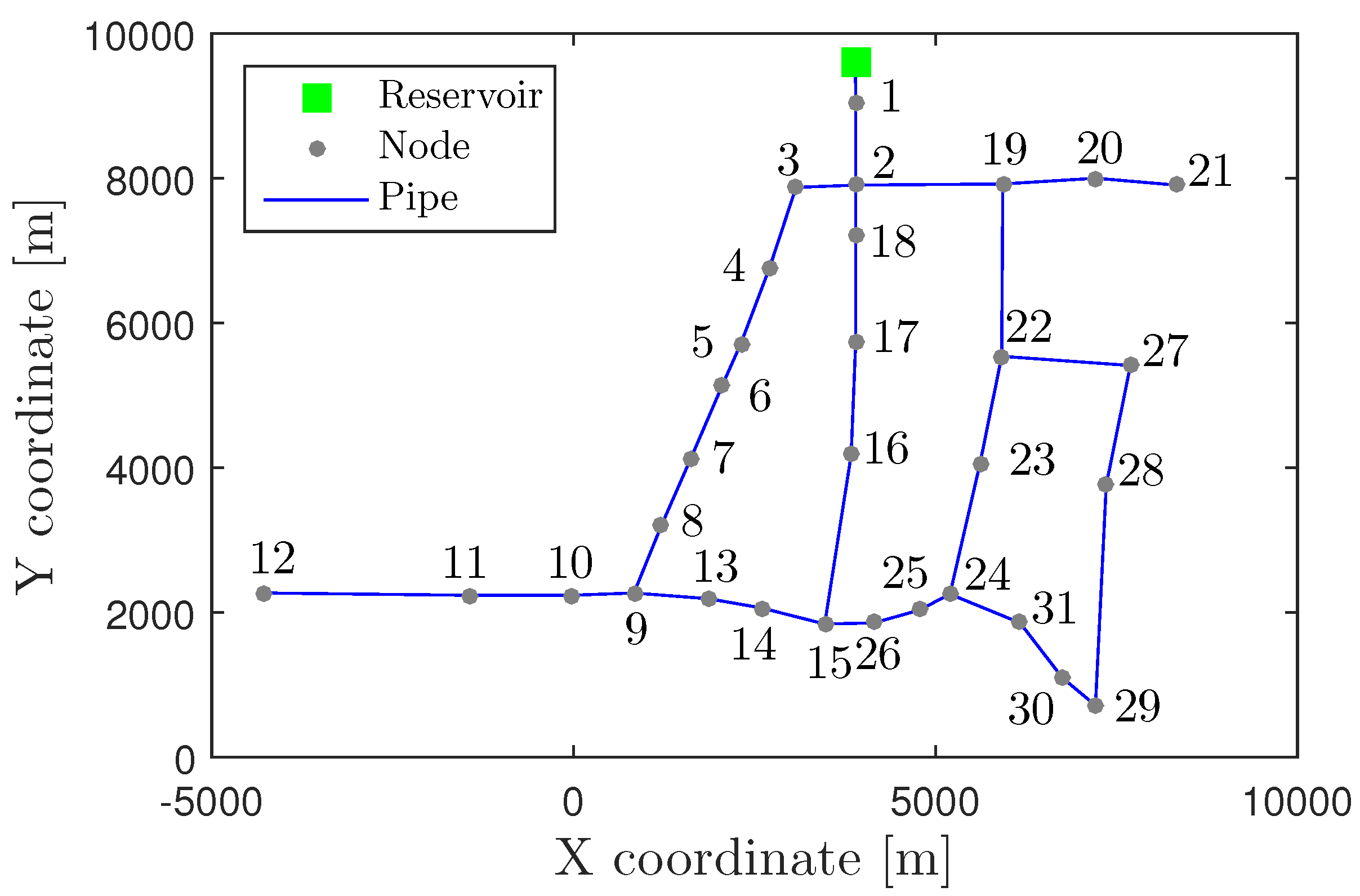
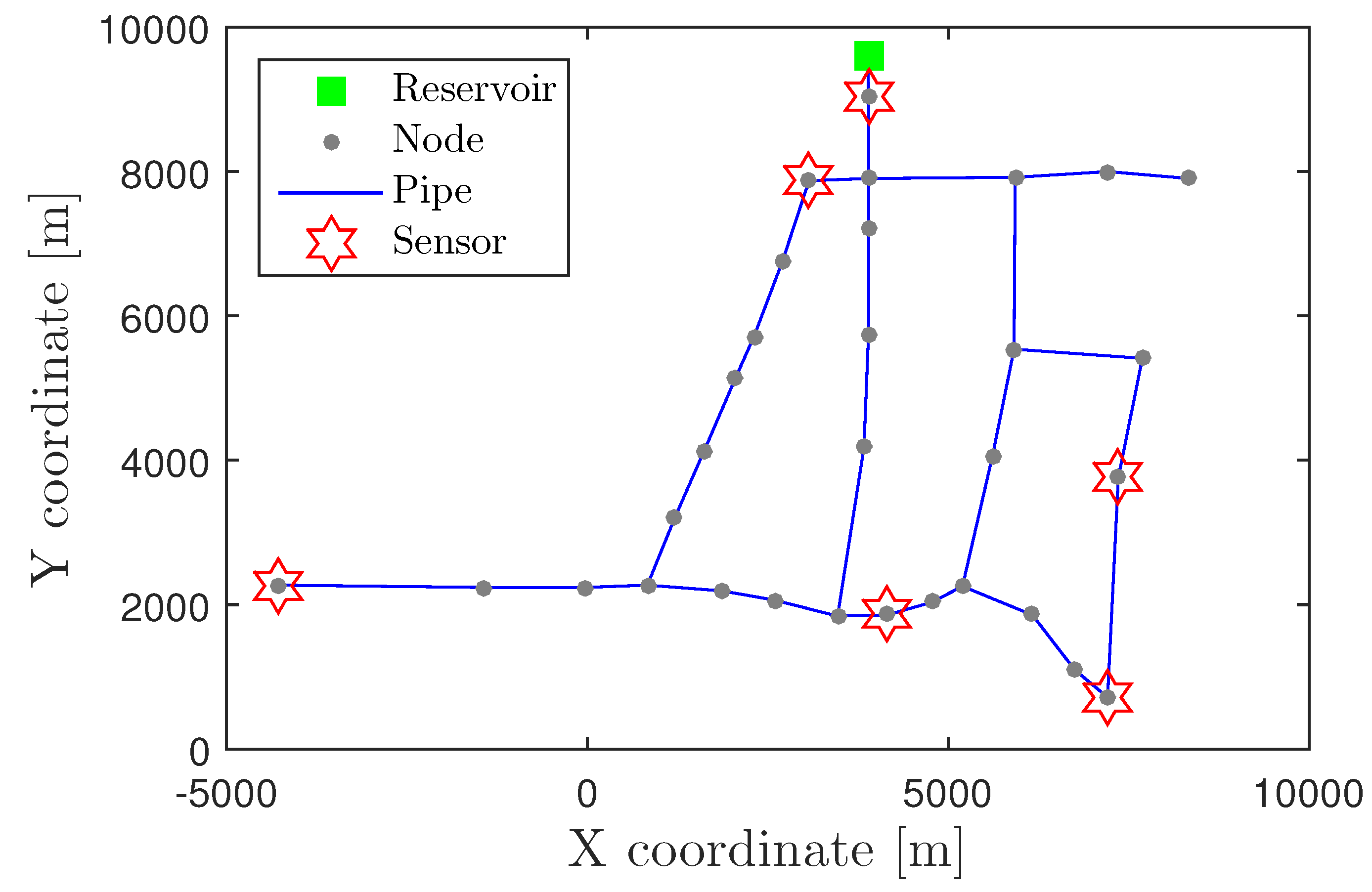
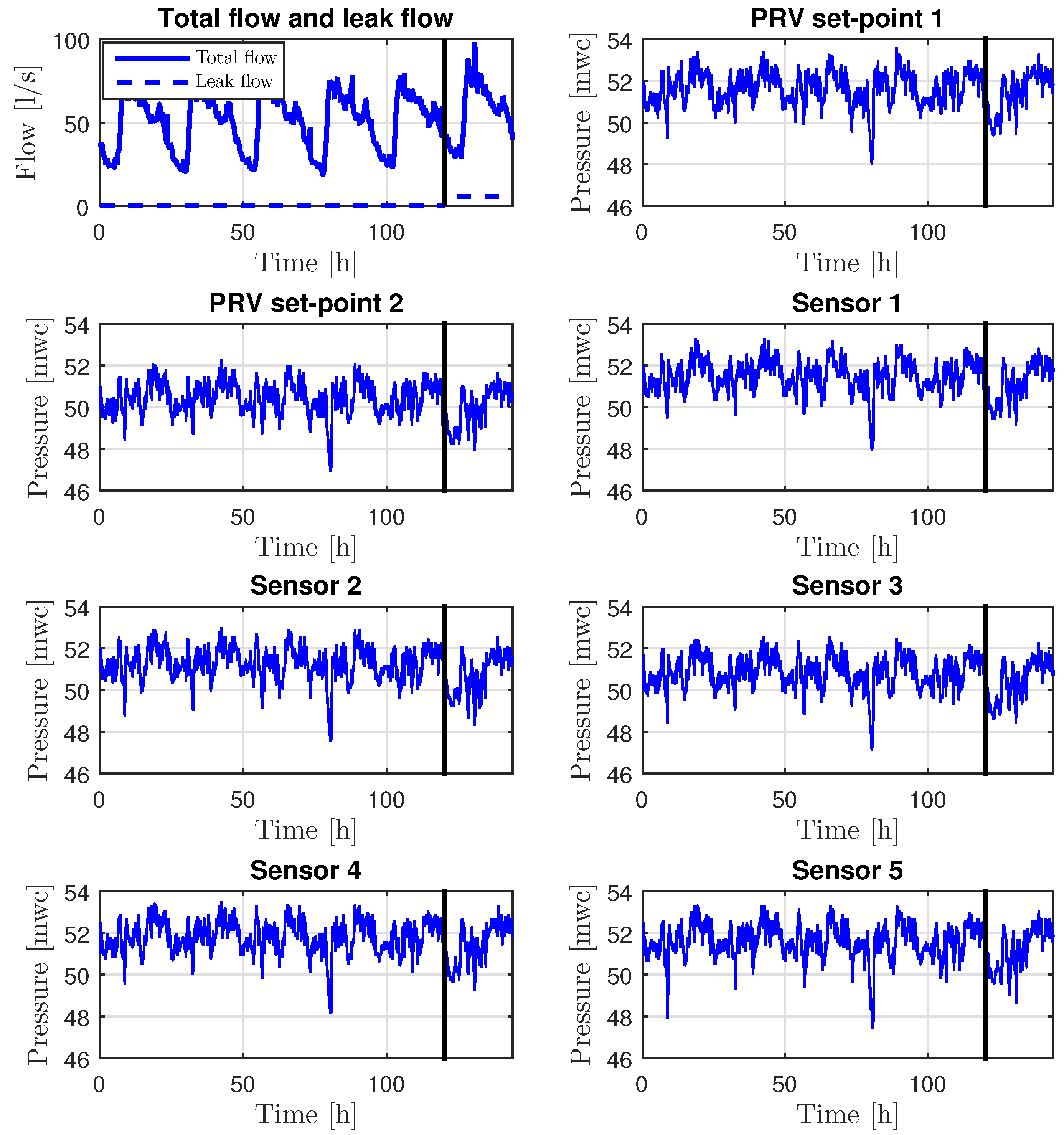
4.1. Hanoi WDN Case Study
- The leak uncertainty is taken into account by considering that the exact leak size is not known but it is contained in the range of 25 and 75 .
- The noise in the measurements is emulated by adding white noise of the amplitude of 0.1 (zero mean) meter water column ().
- The demand uncertainty is considered by introducing an uncertainty of the 10 of the nominal demand value.
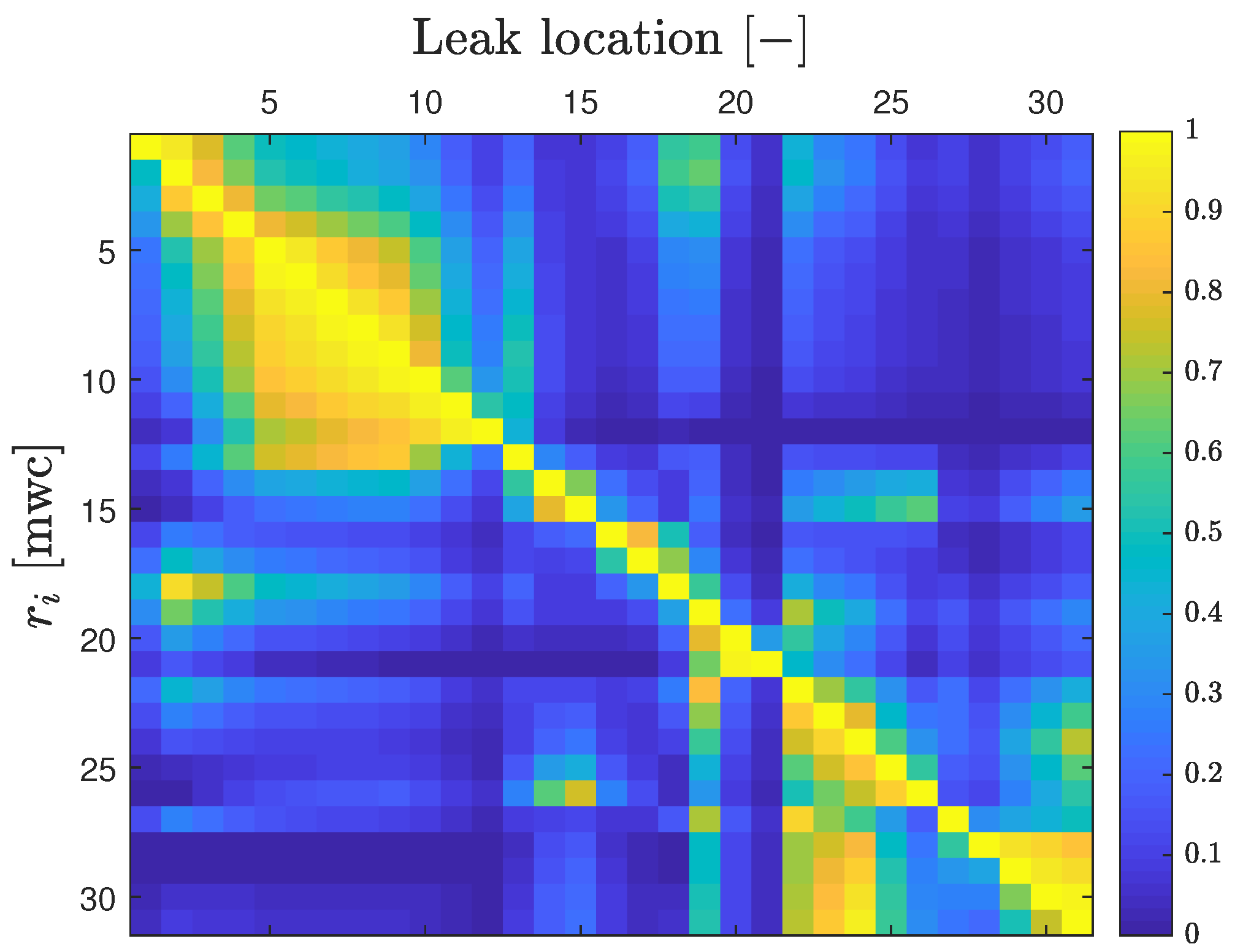
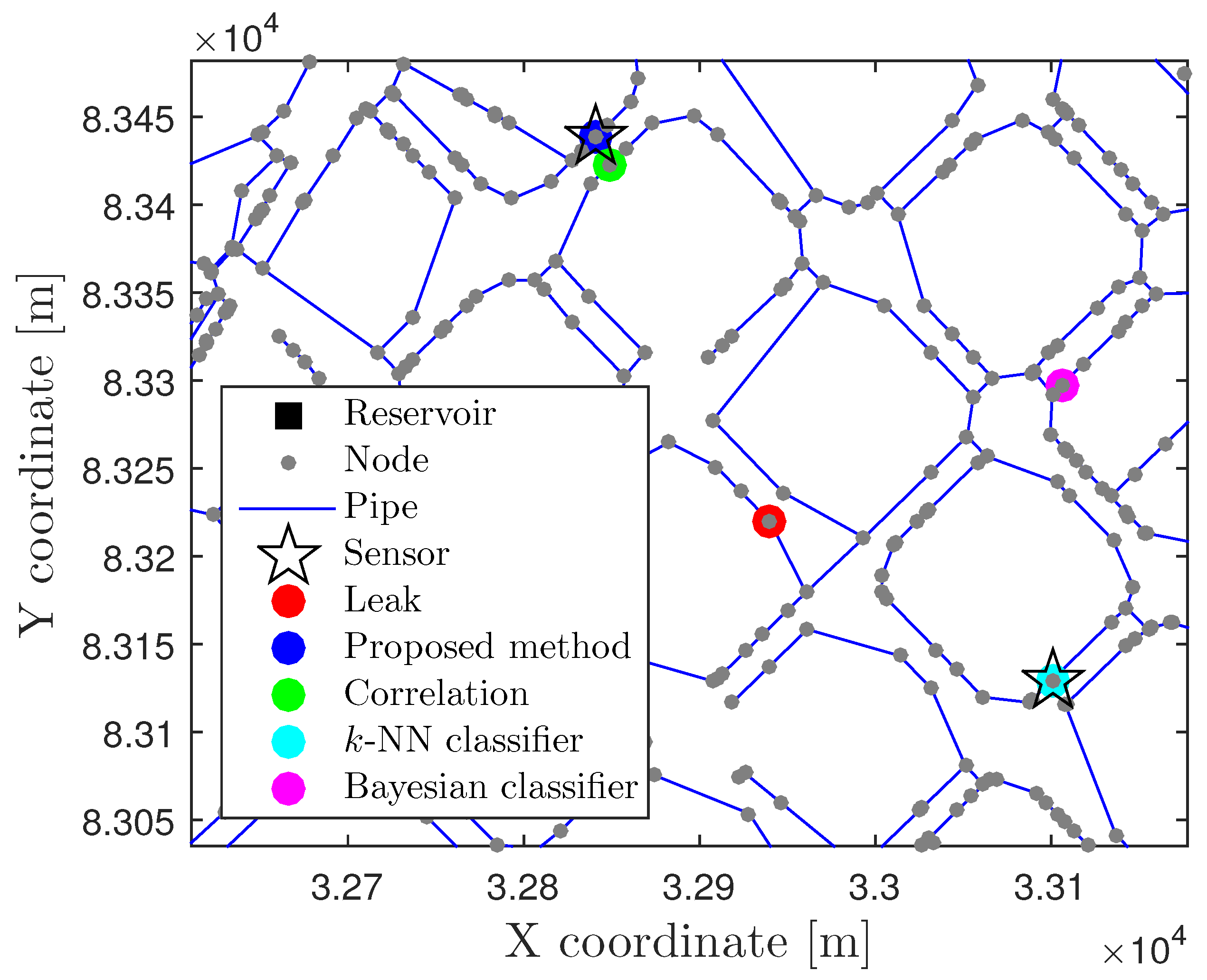
4.1.1. Leak localization Assessment in the Ideal Case
4.1.2. Sensor Placement
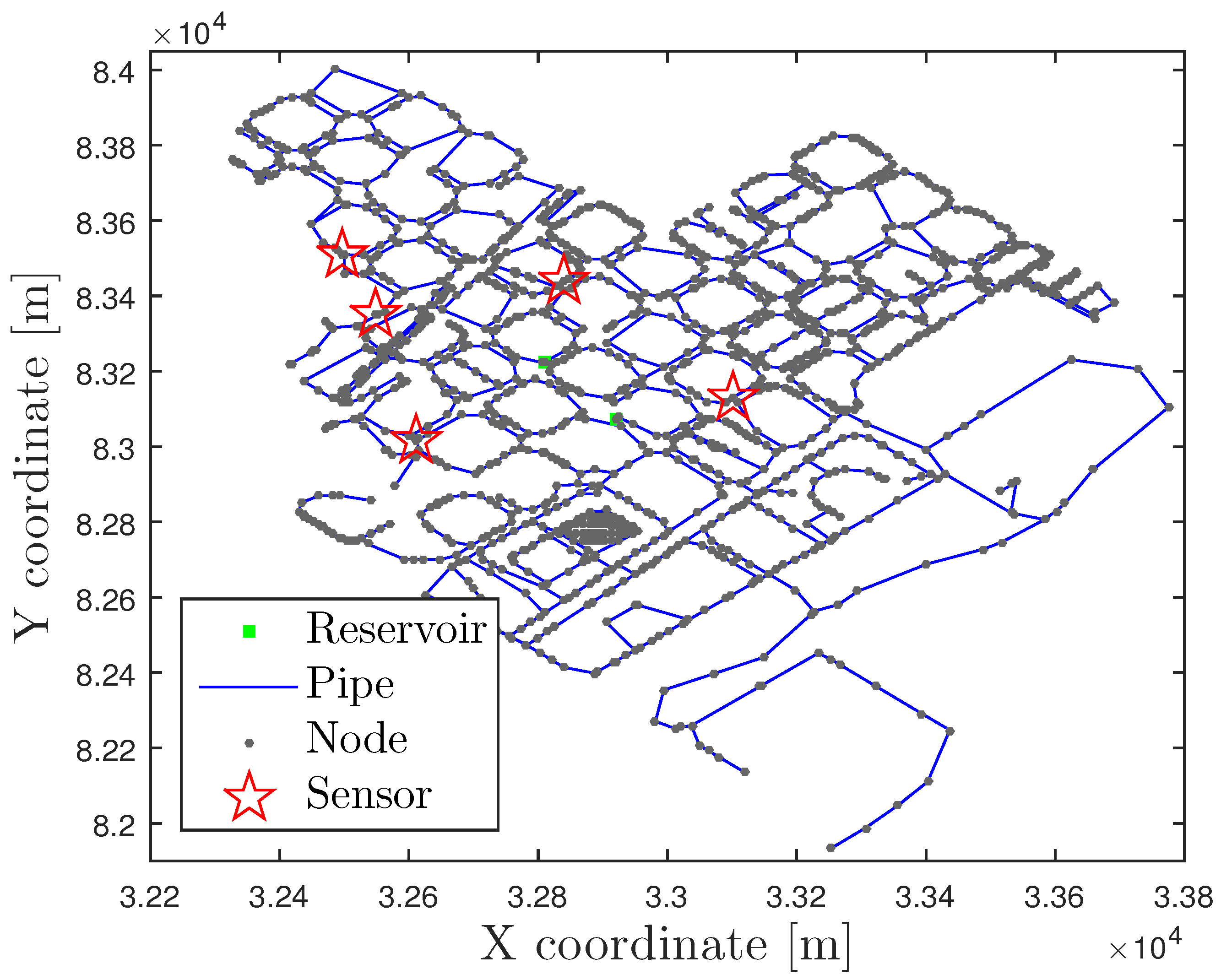
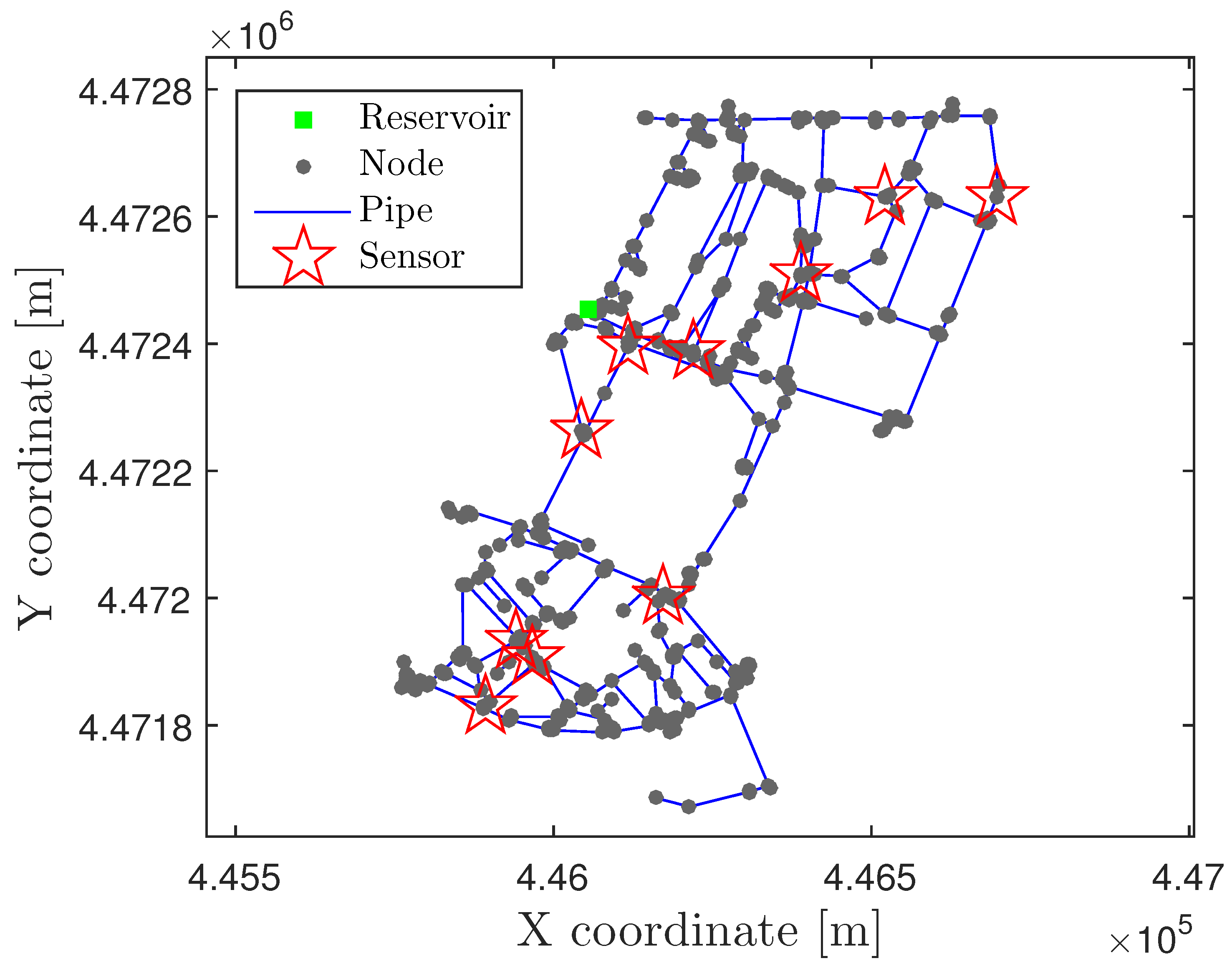
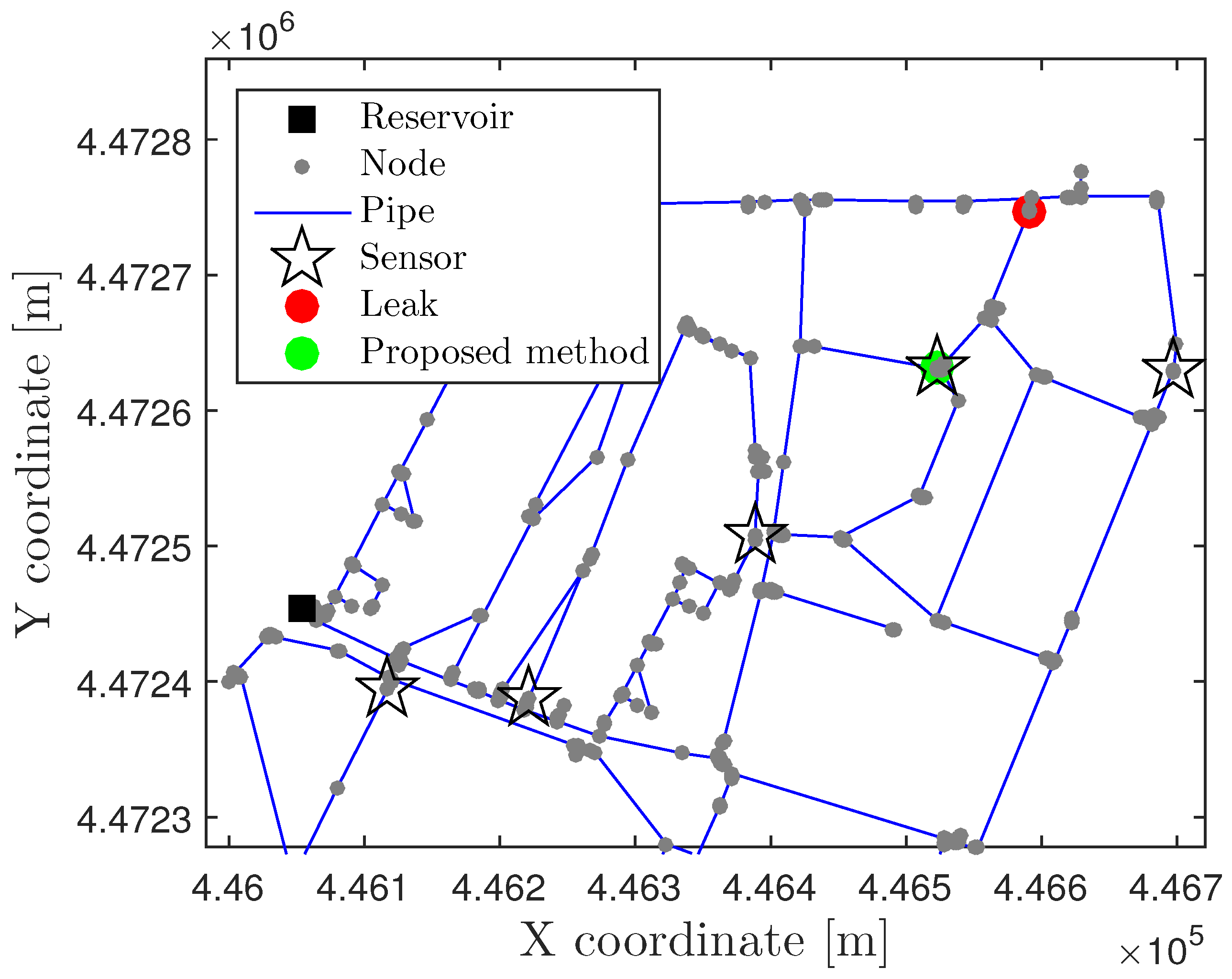
4.2. Nova Icària DMA Case Study
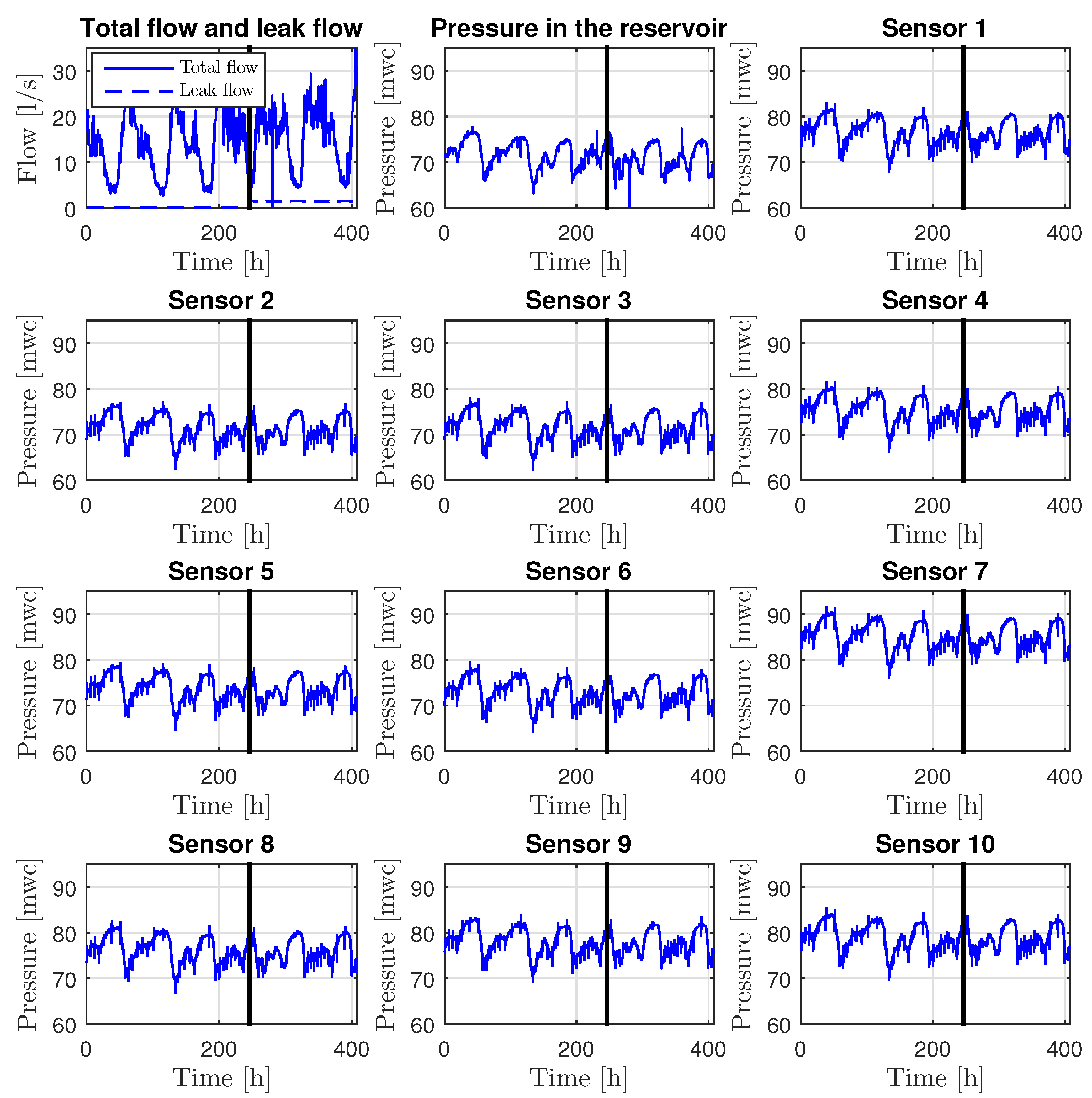
4.3. Madrid DMA Case Study
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Puust, R.; Kapelan, Z.; Savić, D.A.; Koppel, T. A review of methods for leakage management in pipe networks. Urban Water J. 2010, 7, 25–45. [Google Scholar] [CrossRef]
- Khulief, Y.; Khalifa, A.; Mansour, R.; Habib, M. Acoustic Detection of Leaks in Water Pipelines Using Measurements inside Pipe. J. Pipeline Syst. Eng. Pract. 2012, 3, 47–54. [Google Scholar] [CrossRef]
- Lambert, M.F.; Simpson, A.R.; Vítkovský, J.P.; Wang, X.J.; Lee, P.J. A Review of Leading-edge Leak Detection Techniques for Water Distribution Systems. In Proceedings of the 20th AWA Convention, Perth, Australia, 26–28 September 2003. [Google Scholar]
- Lambert, A. What do we know about pressure:leakage relationships in distribution systems? In Proceedings of the IWA Conference System Approach to Leakage Control and Water Distribution System Management, Brno, Czech Rebublic, 16–18 May 2001.
- Thornton, J.; Lambert, A. Progress in practical prediction of pressure: leakage, pressure: Burst frequency and pressure: Consumption relationships. In Proceedings of the IWA Special Conference’ Leakage, Halifax, NS, Canada, 12–14 September 2005. [Google Scholar]
- Wu, Z.Y.; Sage, P. Water Loss Detection via Genetic Algorithm Optimization-based Model Calibration. In Proceedings of the Systems Analysis Symposium ASCE, Cincinnati, OH, USA, 27–30 August 2006; pp. 1–11. [Google Scholar]
- Colombo, A.; Lee, P.; Karney, B. A selective literature review of transient-based leak detection methods. J. Hydro-Environ. Res. 2009, 2, 212–227. [Google Scholar] [CrossRef]
- Yang, J.; Wen, Y.; Li, P. Leak location using blind system identification in water distribution pipeline. J. Sound Vib. 2008, 310, 134–148. [Google Scholar] [CrossRef]
- Fuchs, H.; Riehle, R. Ten years of experience with leak detection by acoustic signal analysis. Appl. Acoust. 1991, 33, 1–19. [Google Scholar] [CrossRef]
- Muggleton, J.; Brennan, M.; Pinnington, R. Wavenumber prediction of waves in buried pipes for water leak detection. J. Sound Vib. 2002, 249, 939–954. [Google Scholar] [CrossRef]
- Mashford, J.; de Silva, D.; Marney, D.; Burn, S. An approach to leak detection in pipe networks using analysis of monitored pressure values by support vector machine. In Proceedings of the Third International Conference on Network and System Security, Gold Coast, QLD, Australia, 19–21 June 2009; pp. 534–539. [Google Scholar]
- Ferrandez-Gamot, L.; Busson, P.; Blesa, J.; Tornil-Sin, S.; Puig, V.; Duviella, E.; Soldevila, A. Leak Localization in Water Distribution Networks using Pressure Residuals and Classifiers. IFAC-PapersOnLine 2015, 48, 220–225. [Google Scholar] [CrossRef] [Green Version]
- Wachla, D.; Przystalka, P.; Moczulski, W. A Method of Leakage Location in Water Distribution Networks using Artificial Neuro-Fuzzy System. IFAC-PapersOnLine 2015, 48, 1216–1223. [Google Scholar] [CrossRef]
- Verde, C.; Torres, L. Modeling and Monitoring of Pipelines and Networks: Advanced Tools for Automatic Monitoring and Supervision of Pipelines; Springer: Berlin, Germany, 2017. [Google Scholar]
- Covas, D.; Ramos, H. Hydraulic Transients used for Leak Detection in Water Distribution Systems. In Proceedings of the 4th International Conference on Water Pipeline Systems, York, UK, 28–30 March 2001; pp. 227–241. [Google Scholar]
- Kepler, A.; Covas, D.; Reis, L. Leak detection by inverse transient analysis in an experimental PVC pipe system. J. Hydroinformatics 2011, 13, 153–166. [Google Scholar]
- Ferrante, M.; Brunone, B. Pipe system diagnosis and leak detection by unsteady-state tests. 1. Harmonic analysis. Adv. Water Resour. 2003, 26, 95–105. [Google Scholar] [CrossRef]
- Ferrante, M.; Brunone, B. Pipe system diagnosis and leak detection by unsteady-state tests. 2. Wavelet analysis. Adv. Water Resour. 2003, 26, 107–116. [Google Scholar] [CrossRef]
- Pudar, R.S.; Liggett, J.A. Leaks in Pipe Networks. J. Hydraul. Eng. 1992, 118, 1031–1046. [Google Scholar] [CrossRef]
- Savić, D.Z.; Kapelan, Z.; Jonkergouw, P. Quo vadis water distribution model calibration? Urban Water J. 2009, 6, 3–22. [Google Scholar]
- Pérez, R.; Puig, V.; Pascual, J.; Quevedo, J.; Landeros, E.; Peralta, A. Methodology for leakage isolation using pressure sensitivity analysis in water distribution networks. Control. Eng. Pract. 2011, 19, 1157–1167. [Google Scholar] [CrossRef] [Green Version]
- Casillas, M.V.; Garza-Castañón, L.; Puig, V. Extended-Horizon Analysis of Pressure Sensitivities for Leak Detection in Water Distribution Networks. In Proceedings of the 8th IFAC Symposium on Fault Detection, Supervision and Safety of Technical Processes, Mexico City, Mexico, 29–31 August 2012; Elsevier: Amsterdam, The Netherlands, 2012; pp. 570–575. [Google Scholar]
- Pérez, R.; Sanz, G.; Puig, V.; Quevedo, J.; Nejjari, F.; Meseguer, J.; Cembrano, G.; Mirats, J.; Sarrate, R. Leak Localization in Water Networks. IEEE Control. Syst. Mag. 2014, 34, 24–36. [Google Scholar]
- Soldevila, A.; Blesa, J.; Tornil-Sin, S.; Duviella, E.; Fernandez-Canti, R.M.; Puig, V. Leak localization in water distribution networks using a mixed model-based/data-driven approach. Control. Eng. Pract. 2016, 55, 162–173. [Google Scholar] [CrossRef] [Green Version]
- Soldevila, A.; Fernandez-Canti, R.M.; Blesa, J.; Tornil-Sin, S.; Puig, V. Leak localization in water distribution networks using Bayesian Classifiers. J. Process Control 2017, 55, 1–9. [Google Scholar] [CrossRef]
- Casillas, M.V.; Garza-Castañón, L.E.; Puig, V. Extended-horizon analysis of pressure sensitivities for leak detection in water distribution networks: Application to the Barcelona network. In Proceedings of the 2013 European Control Conference (ECC), Zurich, Switzerland, 17–19 July 2013. [Google Scholar]
- Jensen, T.; Kallesøe, C. Application of a Novel Leakage Detection Framework for Municipal Water Supply on AAU Water Supply Lab. In Proceedings of the 2016 3rd Conference on Control and Fault-Tolerant Systems (SysTol), Barcelona, Spain, 7–9 September 2016; pp. 428–433. [Google Scholar]
- Romano, M.; Woodward, K.; Kapelan, Z. Statistical Process Control Based System for Approximate Location of Pipe Bursts and Leaks in Water Distribution Systems. Procedia Eng. 2017, 186, 236–243. [Google Scholar] [CrossRef]
- Kleijnen, J.P. Regression and Kriging metamodels with their experimental designs in simulation: A review. Eur. J. Oper. Res. 2017, 256, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, H.B.; Lophaven, S.N.; Søndergaard, J. DACE—A Matlab Kriging Toolbox; Technical University of Denmark: Lyngby, Denmark, 2002. [Google Scholar]
- Rico-Ramirez, V.; Frausto-Hernandez, S.; Diwekar, U.M.; Hernandez-Castro, S. Water networks security: A two-stage mixed-integer stochastic program for sensor placement under uncertainty. Comput. Chem. Eng. 2007, 31, 565–573. [Google Scholar] [CrossRef]
- Eliades, D.G.; Polycarpou, M.M.; Charalambous, B. A Security-Oriented Manual Quality Sampling Methodology for Water Systems. Water Resour. Manag. 2011, 25, 1219–1228. [Google Scholar] [CrossRef]
- Rathi, S.; Gupta, R.; Kamble, S.; Sargaonkar, A. Risk Based Analysis for Contamination Event Selection and Optimal Sensor Placement for Intermittent Water Distribution Network Security. Water Resour. Manag. 2016, 30, 2671–2685. [Google Scholar] [CrossRef]
- Christodoulou, S.E.; Gagatsis, A.; Xanthos, S.; Kranioti, S.; Agathokleous, A.; Fragiadakis, M. Entropy-Based Sensor Placement Optimization for Waterloss Detection in Water Distribution Networks. Water Resour. Manag. 2013, 27, 4443–4468. [Google Scholar] [CrossRef]
- Sarrate, R.; Blesa, J.; Nejjari, F.; Quevedo, J. Sensor placement for leak detection and location in water distribution networks. Water Sci. Technol. Water Supply 2014, 14, 795–803. [Google Scholar] [CrossRef] [Green Version]
- Casillas, M.V.; Puig, V.; Garza-Castañón, L.E.; Rosich, A. Optimal Sensor Placement for Leak Location in Water Distribution Networks Using Genetic Algorithms. Sensors 2013, 13, 14984–15005. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Steffelbauer, D.B.; Fuchs-Hanusch, D. Efficient Sensor Placement for Leak Localization Considering Uncertainties. Water Resour. Manag. 2016, 30, 5517–5533. [Google Scholar] [CrossRef] [Green Version]
- Cugueró-Escofet, M.A.; Puig, V.; Quevedo, J. Optimal pressure sensor placement and assessment for leak location using a relaxed isolation index: Application to the Barcelona water network. Control. Eng. Pract. 2017, 63, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Blesa, J.; Nejjari, F.; Sarrate, R. Robust sensor placement for leak location: analysis and design. J. Hydroinformatics 2016, 18, 136–148. [Google Scholar] [CrossRef]
- Soldevila, A.; Blesa, J.; Tornil-Sin, S.; Fernandez-Canti, R.M.; Puig, V. Sensor placement for classifier-based leak localization in water distribution networks using hybrid feature selection. Comput. Chem. Eng. 2018, 108, 152–162. [Google Scholar] [CrossRef] [Green Version]
- Pudil, P.; Novovičová, J.; Kittler, J. Floating search methods in feature selection. Pattern Recognit. Lett. 1994, 15, 1119–1125. [Google Scholar] [CrossRef]
- Rossman, L. EPANET 2 User’s Manual; United States Envionmental Protection Agency: Washington, DC, USA, 2000.
- Cugueró-Escofet, P.; Blesa, J.; Pérez, R.; Cugueró-Escofet, M.A.; Sanz, G. Assessment of a Leak Localization Algorithm in Water Networks under Demand Uncertainty. IFAC-PapersOnLine 2015, 48, 226–231. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ⋯ | ⋯ | ||||
|---|---|---|---|---|---|
| ⋯ | ⋯ | ||||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| ⋯ | ⋯ | ||||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| ⋯ | ⋯ |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Soldevila, A.; Blesa, J.; Fernandez-Canti, R.M.; Tornil-Sin, S.; Puig, V. Data-Driven Approach for Leak Localization in Water Distribution Networks Using Pressure Sensors and Spatial Interpolation. Water 2019, 11, 1500. https://doi.org/10.3390/w11071500
Soldevila A, Blesa J, Fernandez-Canti RM, Tornil-Sin S, Puig V. Data-Driven Approach for Leak Localization in Water Distribution Networks Using Pressure Sensors and Spatial Interpolation. Water. 2019; 11(7):1500. https://doi.org/10.3390/w11071500
Chicago/Turabian StyleSoldevila, Adrià, Joaquim Blesa, Rosa M. Fernandez-Canti, Sebastian Tornil-Sin, and Vicenç Puig. 2019. "Data-Driven Approach for Leak Localization in Water Distribution Networks Using Pressure Sensors and Spatial Interpolation" Water 11, no. 7: 1500. https://doi.org/10.3390/w11071500